논문 링크 : https://arxiv.org/abs/1612.08242
Contribution
기존 YOLO v1 모델을 보완하여 정확도를 높인 YOLO v2 모델을 제시
Motivation
YOLO v1의 경우, 속도는 빨라졌으나 정확도는 기존 sota 모델 대비 부족하였다
Core Idea
- Better : 정확도를 올리기 위한 방법
- Faster : detection 속도를 향상시키기 위한 방법
- Stronger : 더 많은 범위의 class를 예측하기 위한 방법
1. Better
- Batch Normalization
- High Resolution Classifier
- Convolutional With Anchor Boxes
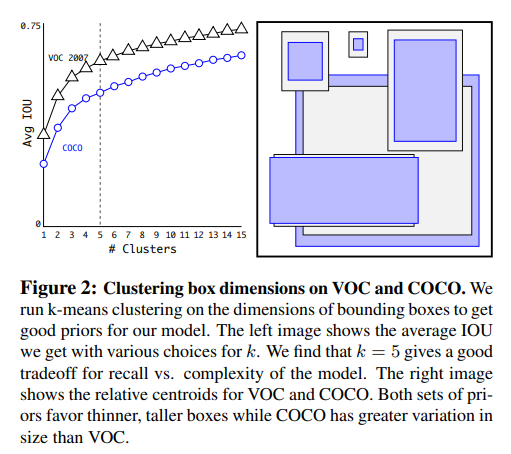
- Dimension Cluster
- Direct Location Prediction
- Fine-Grained Features
- Multi-Scale Training
1. Batch Normalization의 적용
conv layer에 모두 batch normalization을 적용 => mAP 2% 성능 향상
2. High Resolution Classifier
- YOLO v1에서 feature extraction 목적으로 사용된 CNN모델은 VGG 16
- VGG 16은 224x224 image에 대한 객체를 classification하는데 최적화
- YOLO v1을 보면 detection을 위해 input image size가 두 배더 커진 448x448 image => 448x448 image에 익숙하지 않았던 VGG 16 기반의 CNN 모델이 detection에서 성능저하를 일으킴
- YOLO v2에서는 imageNet의 dataset에서 448x448 이미지들을 다시 학습시켜 fine-tuning => mAP가 4% 향상
3. Convolutional With Anchor Boxes
- YOLO v1은 BB(Bounding Box)를 구할 때, (x,y,w,h) 값을 랜덤하게 설정해주고, 직접 최적화된 값을 찾아가도록 학습 => 예측하는 박스의 크기나 위치를 찾아가는 과정이 쉽지 않음
- Faster R-CNN에서는 anchor box 9개를 설정해주고, bounding box regression을 통해 x, y, aspect ratio (offset)값과 object confidence score를 계산하였음 => YOLO v2에서도 Anchor box를 사용, 다만, Faster R-CNN에서는 anchor box의 크기와 aspect ratio를 사전에 미리 정의하였던 것과는 달리, YOLO v2는 [4. Dimension Cluster]에 나와있는 것 처럼, k-means clustering을 통해 최적의 크기와 비율을 찾아준다.
4. Dimension Cluster
5. Direct Location Prediction
- Anchor box를 활용한 바운딩박스 offset 예측법은 BB의 위치를 제한하지 않기 때문에, 초기 학습시 불안정함
- YOLO v1은 그리드의 중심점을 예측했다면, YOLO v2에서는 left top 꼭지점으로부터 얼마나 이동해야 하는지를 학습
- sigmoid 함수를 활용하여 offset의 범위를 0에서 1로 제한
- 모델은 각 바운딩 박스마다 5개의 값 ()을 학습 (to : object 여부)
- px, py, pw, ph : 사전에 정해진 Anchor box의 x, y, w, h
- tx, ty, tw, th : bounding box prediction
- x,y는 grid cell 내부에 중심점을 잡기위해 sigmoid 함수를 통과, w,h는 exponential을 사용해 box의 scale을 조절.

6. Fine-Grained Features
- 상대적으로 작은 feature map에서는 작은 크기의 객체에 대한 localization 작업이 어려움
- YOLO v1에서는 CNN을 통과한 마지막 레이어의 피쳐맵만 사용하여 작은 물체에 대한 정보가 사라짐
- YOLO v2에서는 상위 레이어의 피쳐맵을 하위 레이어의 피쳐맵에 합쳐줌
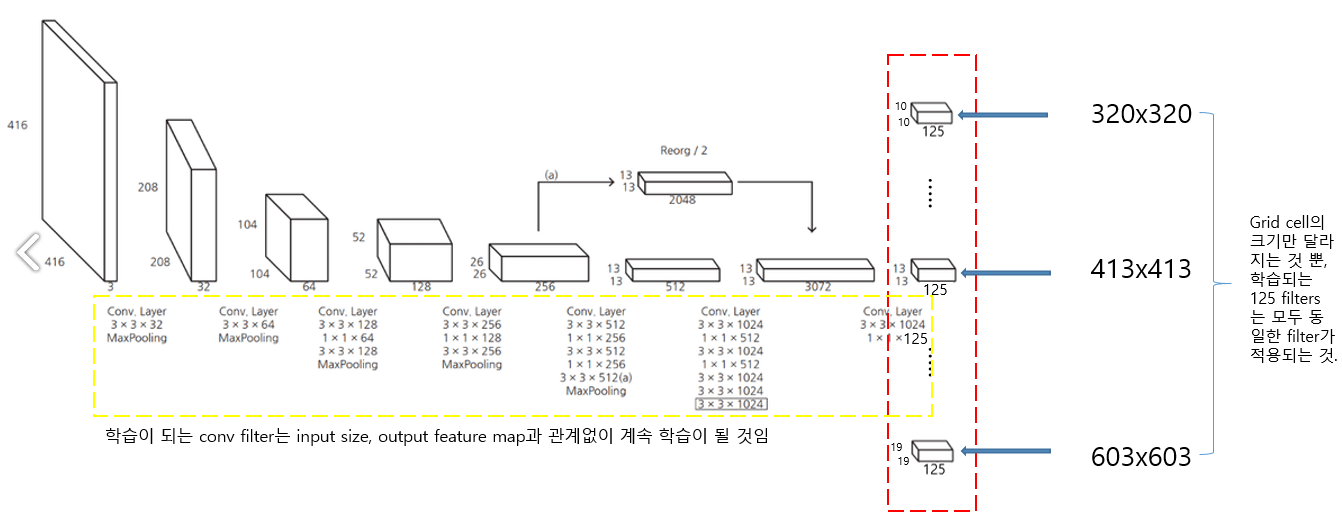
- feature map을 channel은 유지하면서 4개로 분할한 후 결합(concat)하여 13x13x2048 크기의 feature map을 얻은 후, 이를 13x13x1024 feature map와 합쳐, 13x13(x3072) 크기의 feature map을 만듦
- 마지막 13x13x125는 총 5개의 anchor boxes를 적용했다고 가정했을 때, 하나의 cell에서 총 5x25 =125개의 정보를 갖고 있음을 의미 (YOLO V1는 2개의 bounding box가 각각의 cell에 대해 classification 결과를 공유, YOLO V2에서 anchor box를 적용시켰을 때에는 각각의 anchor box에 대해서 classification 정보를 갖고있기 때문에, 하나의 anchor box에 대해 25가지 정보로 구성됨)
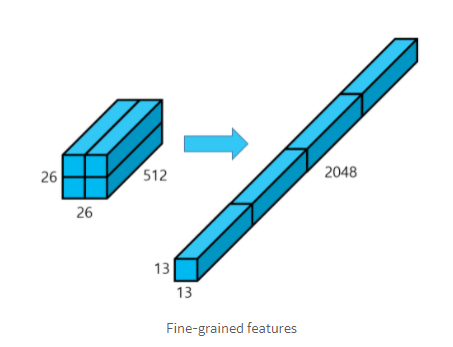
7. Multi-Scale Training
- 작은 물체들을 잘 잡아내기 위해서 여러 스케일의 이미지를 학습할 수 있도록 함
- YOLO V2는 10 batches 마다 input size를 변경시켜 학습
2. Faster
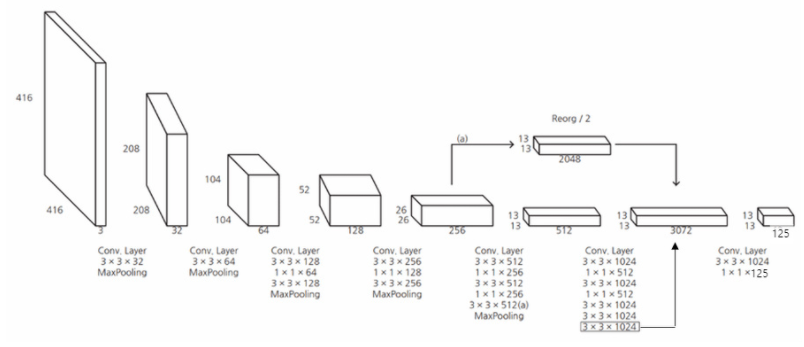
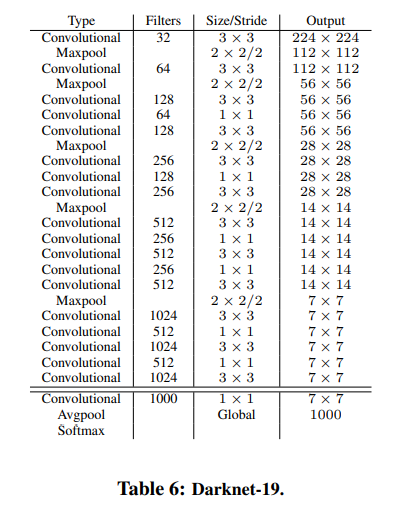
- Darknet-19라는 독자적인 classification 모델을 backbone network로 사용
- YOLO v2의 Darknet-19는 마지막 layer에 fc layer를 제거하고, global average pooling을 사용하여 파라미터 수를 감소시키고, detection 속도를 향상시킴
- Darknet-19 네트워크에서 global average pooling 후 ouput의 수가 1000개인 이유 : class의 수가 1000개인 ImageNet 데이터셋을 통해 학습시켰기 때문
- Darknet-19를 Detection task에 사용하기 위해 마지막 conv layer를 3x3(x1024) conv layer로 대체하고, 이후 1x1 conv layer를 추가
3. Stronger
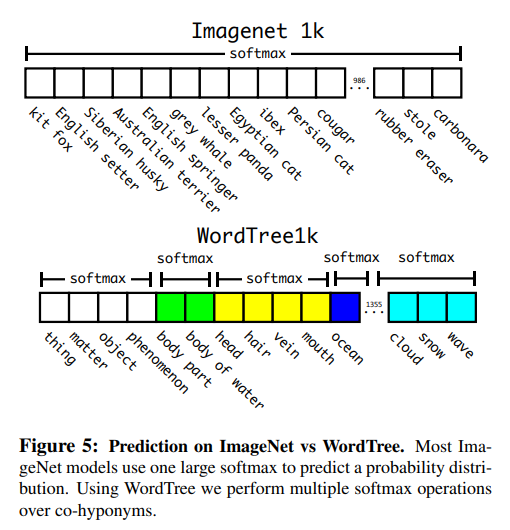
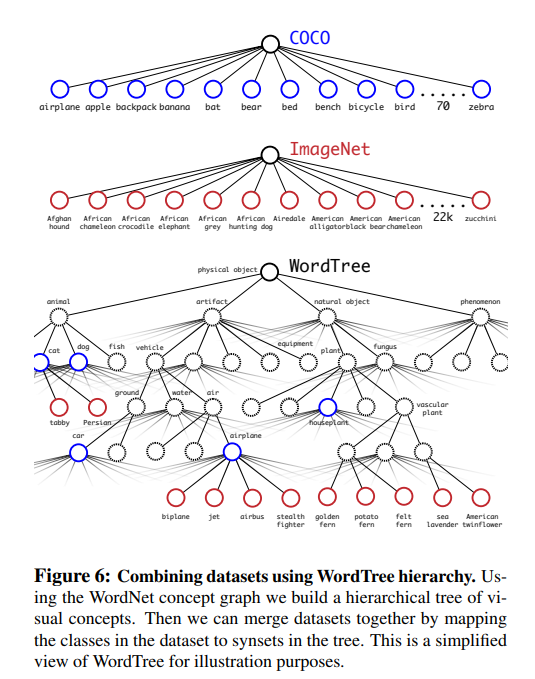
- YOLO v2 아키텍쳐를 기반으로 총 9000개에 달하는 클래스를 잡아내는 YOLO 9000
- 방대한 크기의 class에 대해서 classification을 수행할 경우 계층적으로 분류 작업을 수행해야한다고 제안
기타

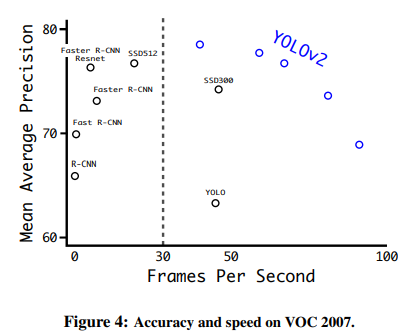
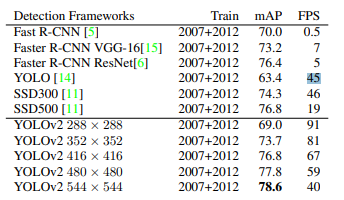
- YOLO v2는 mAP 값이 73.4%
- 입력 이미지의 크기에 따라 정확도와 detection 속도의 trade-off가 발생
- 이미지의 크기가 클 경우 정확도가 높아지지만 detection 속도가 느려짐
반응형
'머신러닝_딥러닝 > Object Detection' 카테고리의 다른 글
| (논문리뷰) SSD (2016) (0) | 2021.09.13 |
|---|---|
| (논문리뷰) SPPnet (0) | 2021.09.13 |
| (논문리뷰) Yolo v1 (2016) (0) | 2021.09.13 |
| (논문리뷰) Faster R-CNN (0) | 2021.09.13 |
| (논문리뷰) Fast R-CNN (0) | 2021.09.13 |