논문링크 : https://pjreddie.com/media/files/papers/YOLOv3.pdf
Contribution
본문의 [Abstract]에 나와있는 바와 같이 기존 YOLO v2에 약간의 변화를 주어 성능향상을 도모하였다.

Motivation
모델이 더 빠르고, 더 정확하면 좋지 않을까요?

Core idea
YOLO v2와 비교하여 달라진 점
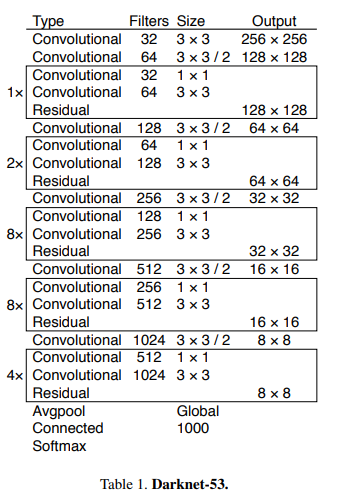
- Darknet-19에서 Darknet-53로 변경
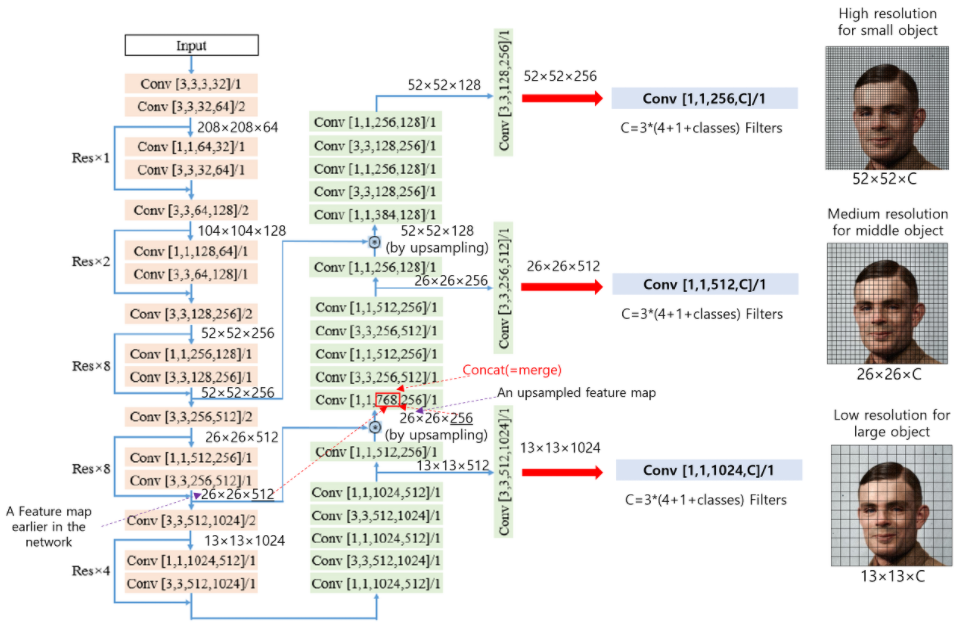
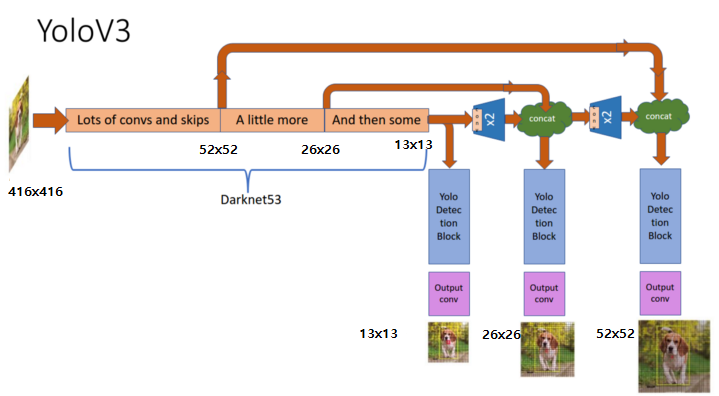
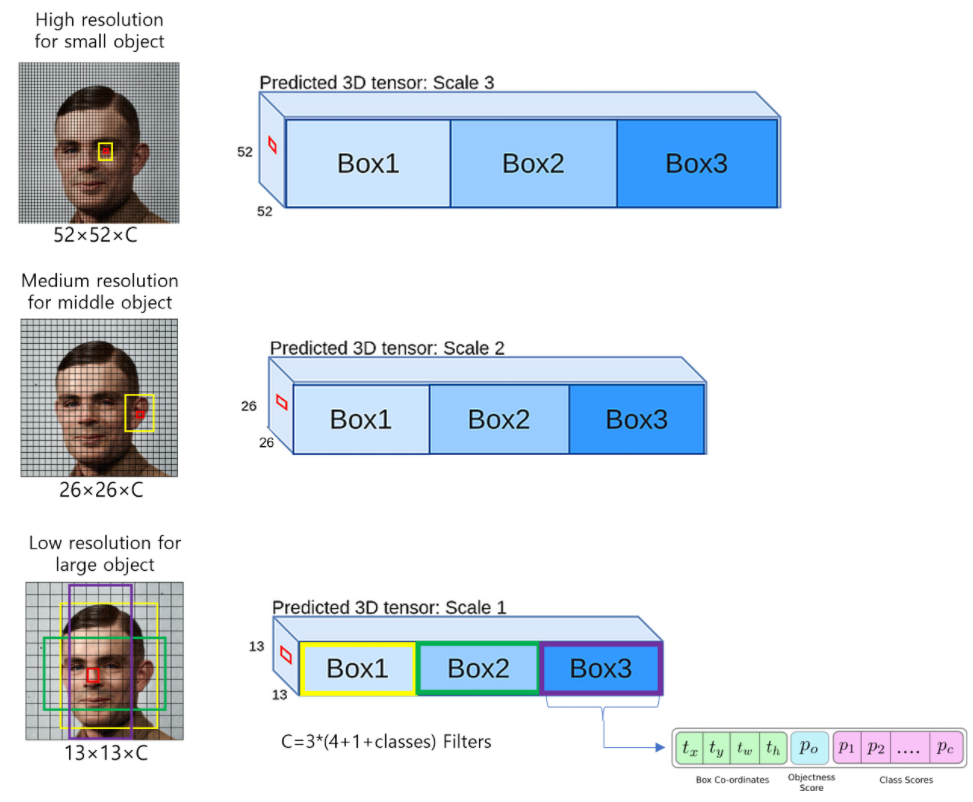
- 다양한 크기의 피쳐맵를 사용하여 바운딩 박스를 예측
- Class prediction을 할 때, Softmax를 사용하지 않고 개별 클래스 별로 sigmoid를 사용 (binary classification)
Darknet-53
- ResNet에서 제안된 skip connection 개념을 적용하여 레이어를 훨씬 더 많이 쌓았음
- MaxPooling 대신에 컨볼루션의 stride를 2로 취해주어 피쳐맵의 크기를 줄였음
- 마지막 레이어에서 Global Average Pooling
일반적인 classification은 softmax를 취해준 후, cross entropy를 계산. 그 과정에서, softmax를 취해주면 제일 높은 하나의 클래스 확률 값만 지나치게 높게 나타남. -> 입력 이미지에는 하나의 클래스만 있을 것이라는 가정을 하기 때문임


Bounding Box Prediction

bounding box 갯수 : 10647개 (52×52×3+26×26×3+13×13×3)
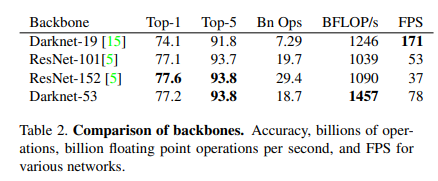
기타
논문에 소개되어 있는, 무쓸모 였던 기법들
- 앵커 박스 x, y의 offset을 너비나 높이의 비율로 예측하는 기법 -> 모델 학습을 불안정하게 함
- 바운딩 박스의 x, y를 예측하는데 비선형 활성화 함수 말고 그냥 선형 함수를 사용 -> 효과 無
- RetinaNet의 Focal Loss를 적용 -> 효과 無
- 예측한 바운딩 박스가 True라고 판단할 IoU 기준 값을 0.3부터 0.7 사이로 설정 -> 효과 無
반응형
'머신러닝_딥러닝 > Object Detection' 카테고리의 다른 글
| (논문리뷰) Deformable Convolution Network, DCN (2017) (0) | 2021.09.13 |
|---|---|
| (논문리뷰) R-FCN (2016) (0) | 2021.09.13 |
| (논문리뷰) Mask R-CNN (0) | 2021.09.13 |
| (논문리뷰) RetinaNet (2017) (0) | 2021.09.13 |
| (논문리뷰) OHEM (2016) (0) | 2021.09.13 |