논문링크 : https://arxiv.org/pdf/1605.06409.pdf
- Object Detection via Region based Fully Convolutional Networks
- two-stage detector
- not per-region computation
Contribution
Faster R-CNN 골격을 유지하되, RPN 이후의 단계를 개선하여 속도를 향상시킴

Motivation

- translation invariance dilmma : feature를 추출하는 역할을 수행하는 backbone network와 detection을 수행하는 network는 각각 translation invariance한 속성( 입력값의 위치가 변해도 출력값은 동일할 경우)과 translation variance한 속성(입력값의 위치가 변하면 출력값이 달라질 경우)을 가지고 있다. 이 때, backbone network에 입력하여 얻은 feature map은 위치 정보가 소실된 채로 detection network로 입력되고, detection network는 객체에 대한 위치 정보가 소실된 feature map이 입력되어 적절하게 학습이 이뤄지지 않는데, 이를 translation invariance dilmma라 한다.
- ResNet+Faster R-CNN 모델은 두 conv layer 사이에 RoI pooling을 삽입하여 region specific한 연산을 추가 -> 이를 통해 RoI pooling layer 이후 conv layer는 translation variance한 속성을 학습할 수 있게됨
- 위 방식은 비록 성능은 높일 수 있을지라도, 모든 RoI를 개별적으로 conv, fc layer에 입력하기 때문에 학습 및 추론 속도가 느려지게 된다.
Core idea
- FCN (Fully Convolutional Network)
- Position-sensitive Score Map & Position-sensitive RoI pooling
FCN (Fully Convolutional Network)
- CNN 모델을 Segemantation에 맞게 변형함
- FC Layer 없이 Convolution Layer로만 구성, Upsampling를 사용함

Position-sensitive Score Map & Position-sensitive RoI pooling
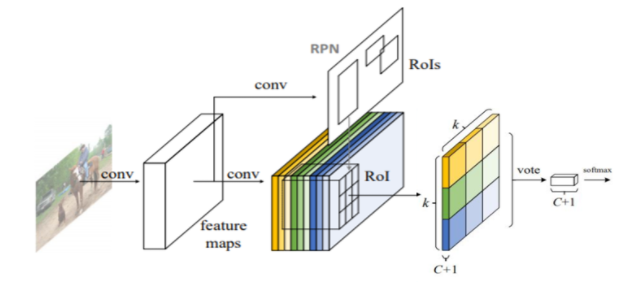
- pre-trained된 ResNet-101 모델의 average pooling layer와 fc layer를 제거하고 오직 conv layer만으로 feature map을 획득
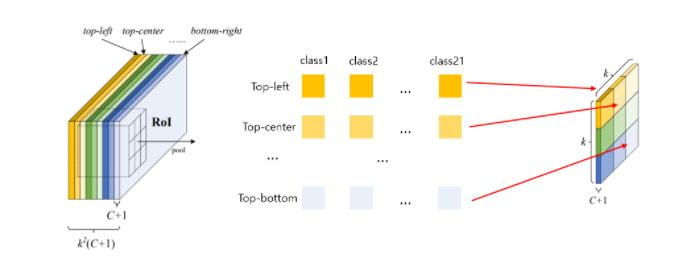
- RPN을 통해 얻은 각각의 RoI에 대하여 class별로 위치 정보를 파악하기 위하여 RoI를 k×k 구간의 grid로 나눠준다.
- feature map의 channel 수가 가 되도록 1x1 conv 연산 수행 -> Position-sensitive score map
- Position-sensitive RoI pooling을 수행 : (top-left의 score map은 top-left의 grid에서만 pooling이 되고, top-center의 score map은 top-centor의 grid에서만 pooling)
- 이후 각 class별로 크기의 feature map의 각 요소들의 평균을 구함 -> voting
- softmax function을 통해 loss 계산
Loss function
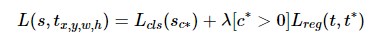
- cross-entropy loss + bounding box regression loss
- 두 loss 사이의 가중치를 조절하는 balancing parameter :
반응형
'머신러닝_딥러닝 > Object Detection' 카테고리의 다른 글
| (논문리뷰) CoupleNet (2017) (0) | 2021.09.13 |
|---|---|
| (논문리뷰) Deformable Convolution Network, DCN (2017) (0) | 2021.09.13 |
| (논문리뷰) Yolo v3 (2018) (0) | 2021.09.13 |
| (논문리뷰) Mask R-CNN (0) | 2021.09.13 |
| (논문리뷰) RetinaNet (2017) (0) | 2021.09.13 |