|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
|
import numpy as np
# 인공 신경망 (Neural Network)
# 인간의 뉴런 구조를 본떠 만든 기계학습 모델
# 시냅스의 결합으로 네트워크를 형성한 인공 뉴런(노드)이 학습을 통해 시냅스의 결합 세기를 변화시켜, 문제 해결 능력을 가지는 모델
# 뉴런(노드)dms 이전 뉴런으로부터 입력을 받아 또 다른 신호를 발생시킴
# 하지만, 입력에 비례해서 출력을 하는 것이 아니라, 임계점을 넘어서야만 출력 신호를 발생시킴 => 활성화 함수
# 대표적인 활성화 함수 => sigmoid, ReLU, Leaky ReLU, hyperbolic tangent etc
# 딥러닝
# 입력층-은닉층-출력층
# 출력층에서의 오차를 기반으로, 오차역전법을 통해, 각 층 노드의 가중치를 학습하는 머신러닝의 한 분야
# 은닉층의 노드의 갯수가 많아지면 당연히 학습속도가 느려지겠죠?
# feed forward : 입력된 데이터가 [입력층-은닉층-출력층]을 흐르는 과정
## XOR 문제 => 딥러닝 네트워크로 해결 ##
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def numerical_derivative(func, x):
delta = 1e-4
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
temp = x[idx]
x[idx] = float(temp) + delta
f1 = func(x)
x[idx] = float(temp) - delta
f2 = func(x)
grad[idx] = (f1 - f2) / (2 * delta)
x[idx] = temp
it.iternext()
return grad
class LogicGate:
def __init__(self, x_data, t_data):
self.__x_data = x_data.reshape(4, 2)
self.__t_data = t_data.reshape(4, 1)
self.__W1 = np.random.rand(2, 8)
self.__b1 = np.random.rand(8)
self.__W2 = np.random.rand(8, 1)
self.__b2 = np.random.rand(1)
self.__learning_rate = 1e-2
def feed_forward(self):
delta = 1e-6 # log가 무한대로 발산하는 것을 막아준다
z1 = np.dot(self.__x_data, self.__W1) + self.__b1
a1 = sigmoid(z1)
z2 = np.dot(a1, self.__W2) + self.__b2
y = sigmoid(z2)
return -np.sum(self.__t_data * np.log(y + delta) + (1 - self.__t_data) * np.log((1 - y) + delta))
def loss_eval(self):
delta = 1e-6 # log가 무한대로 발산하는 것을 막아준다
z1 = np.dot(self.__x_data, self.__W1) + self.__b1
a1 = sigmoid(z1)
z2 = np.dot(a1, self.__W2) + self.__b2
y = sigmoid(z2)
return -np.sum(self.__t_data * np.log(y + delta) + (1 - self.__t_data) * np.log((1 - y) + delta))
def train(self):
f = lambda x: self.feed_forward()
for step in range(10001):
self.__W1 -= self.__learning_rate * numerical_derivative(f, self.__W1)
self.__b1 -= self.__learning_rate * numerical_derivative(f, self.__b1)
self.__W2 -= self.__learning_rate * numerical_derivative(f, self.__W2)
self.__b2 -= self.__learning_rate * numerical_derivative(f, self.__b2)
if (step % 500) == 0:
print("step = ", step, ", error = ", self.loss_eval())
def predict(self, input_data):
z1 = np.dot(input_data, self.__W1) + self.__b1
a1 = sigmoid(z1)
z2 = np.dot(a1, self.__W2) + self.__b2
y = sigmoid(z2)
if y >= 0.5:
result = 1
else:
result = 0
return result
# 테스트 데이터
data_x = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
data_t = np.array([0, 1, 1, 0])
test_data = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
XOR_object = LogicGate(data_x, data_t)
XOR_object.train()
for input_data in test_data:
pred = XOR_object.predict(input_data)
print(input_data, " = ", pred)
|
cs |
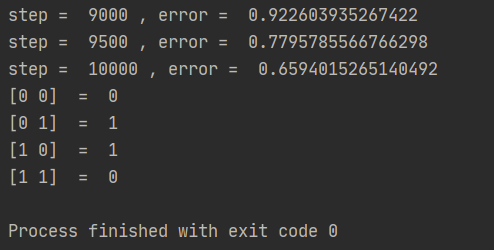
위 소스코드를 실행시키면 아래와 같은 출력값을 얻을 수 있다.
반응형
'머신러닝_딥러닝 > Tensorflow + Keras' 카테고리의 다른 글
| MNIST 2탄 (Back Propagation) (0) | 2021.10.23 |
|---|---|
| MNIST 1탄 (0) | 2021.10.23 |
| XOR 문제 (0) | 2021.10.23 |
| 로지스틱 회귀 (Logistic Regression) (0) | 2021.10.23 |
| 선형회귀 (Linear Regression) (0) | 2021.10.23 |