MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
논문 링크 : https://arxiv.org/abs/1704.04861
Contribution
- Depthwise separable convolution을 활용하여 모델 경량화에 집중 => Accuracy는 약간 떨어졌지만, Parameters는 엄청 줄였음
Motivation
핸드폰이나 임베디드 시스템 같이 저성능·저용량의 메모리환경에서 딥러닝을 적용하기 위해 모델 경량화가 필요

Core Idea
Depthwise separable convolution
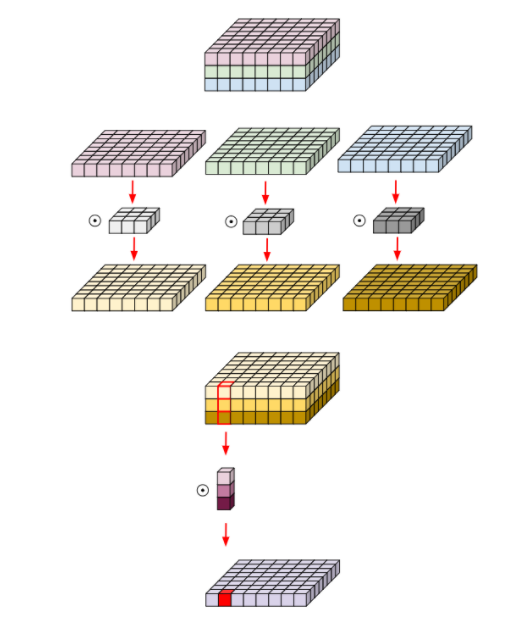
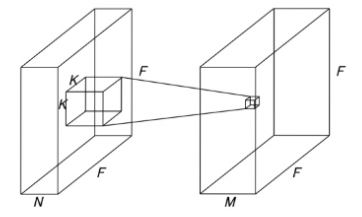
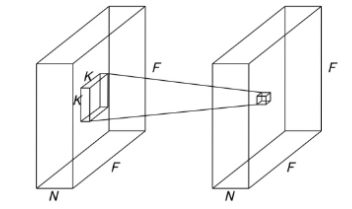
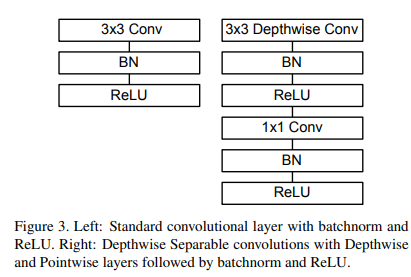
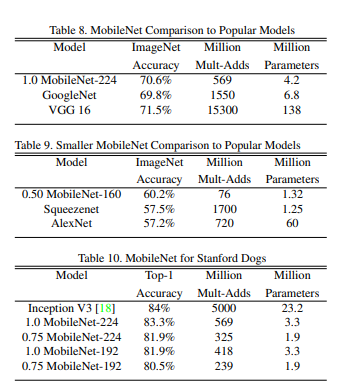
MobileNet Architecture
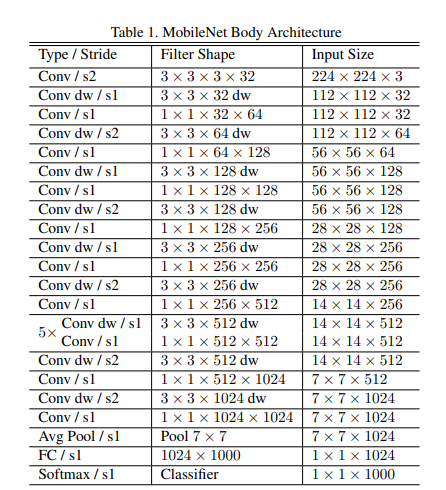
- 대부분의 연산을 FCN대신, 1x1 Conv, 3x3 Conv, Depthwise Separable Convolution을 사용 => 연산량 감소
- 첫번째 레이어는 standard conv를 사용하고, 그 이후부터 depthwise conv와 pointwise conv를 번갈아가며 수행
- feature-map의 크기가 7 x 7 x 1024가 되면, global avg-pooling을 이용하여 1x1x1024로 만들고, 한개의 FC레이어와 softmax를 통해 최종적으로 1 x 1 x 1000 출력
- Width Multiplier : 하이퍼파라미터 α는 MobileNet의 두께를 결정, α는 0~1 범위이고 MobileNet은 1을 사용, input channel M과 output channel(filter개수와 동일) N에 α를 곱해서 채널을 줄이는 역할
- Resolution multiplier : 하이퍼파라미터 ρ는 입력 이미지에 적용하여 해상도를 낮춥니다. 범위는 0~1이고, MobileNet은 ρ=1, 를 input의 width와 height에 곱한다.
기타
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
import torch.nn as nn
class MobileNetV1(nn.Module):
def __init__(self, ch_in, n_classes):
super(MobileNetV1, self).__init__()
self.ch_in = ch_in
self.n_classes = n_classes
def conv_standard(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True))
def conv_dw(inp, oup, stride):
return nn.Sequential(
# depthwise convolution에서는 input의 채널, output의 채널, groups를 모두 같게 하면 ehla
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
# pointwise convolution은 kernel_size는 1로 하시면 됨
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
self.model = nn.Sequential( # input : 224x224x3
conv_standard(self.ch_in, 32, 2), # 112x112x32
conv_dw(32, 64, 1), # 112x112x64
conv_dw(64, 128, 2),
conv_dw(128, 128, 1),
conv_dw(128, 256, 2),
conv_dw(256, 256, 1),
conv_dw(256, 512, 2),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 1024, 2),
conv_dw(1024, 1024, 1),
nn.AdaptiveAvgPool2d(1) # 1x1x1024
)
self.fc = nn.Linear(1024, self.n_classes)
def forward(self, x):
x = self.model(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x
if __name__ == '__main__':
model = MobileNetV1(ch_in=3, n_classes=1000)
|
cs |
반응형
'머신러닝_딥러닝 > 모델 경량화' 카테고리의 다른 글
| (논문리뷰) AmoebaNet (작성예정) (0) | 2021.12.05 |
|---|---|
| (논문리뷰) EfficientNet (작성예정) (0) | 2021.12.01 |
| (논문리뷰) ShuffleNet (0) | 2021.12.01 |
| 모델 경량화 기술 동향 (0) | 2021.12.01 |