ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
논문 링크 : https://arxiv.org/abs/1707.01083
Contribution
Pointwise group convolution과 Channel shuffle을 사용하여 연산량을 더 줄임
Motivation
- prameter수와 computational cost를 줄이고 싶다
- MobileNet에서 보면, 대부분의 연산량이 1x1 conv에 집중 => 마른 수건도 쥐어 짜보자
Core Idea
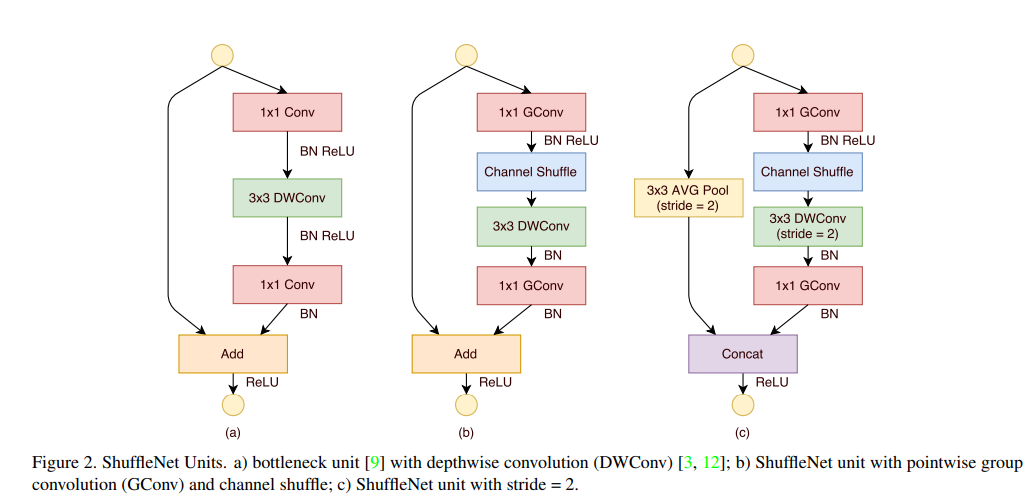
Pointwise Group convolution
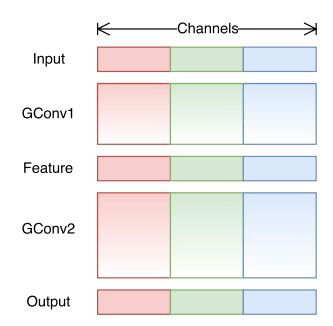
- 1x1 Pointwise Convolution의 연산량을 감소시키기 위해서 제안됨
- Input이 들어오면 그 channel들을 group의 수 만큼 나누어 준 후, 각 group들마다 Conv을 수행, 연산량 감소
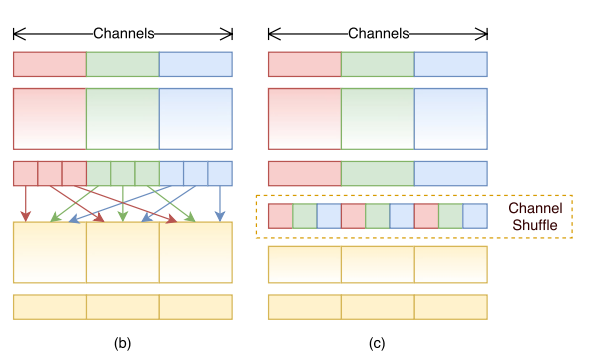
- 문제점 : 각 group사이의 교류(cross talk)가 없음 => 해당 group들 내부에서만 정보가 flow
- 위 문제를 해결하기 위한 방법 => channel shuffle
def channel_shuffle(name, x, num_groups):
with tf.variable_scope(name) as scope:
n, h, w, c = x.shape.as_list() # n은 batchsize, h는 height, w는 width, c는 channel
x_reshaped = tf.reshape(x, [-1, h, w, num_groups , c//num_groups])
x_transposed = tf.transpose(x_reshaped, [0, 1, 2, 4, 3])
output = tf.reshape(x_transposed, [-1, h, w, c]) # flatten
return output
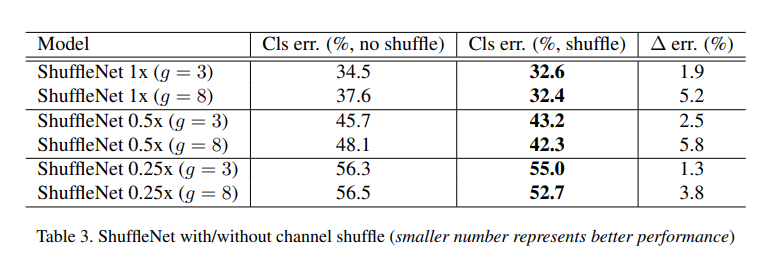
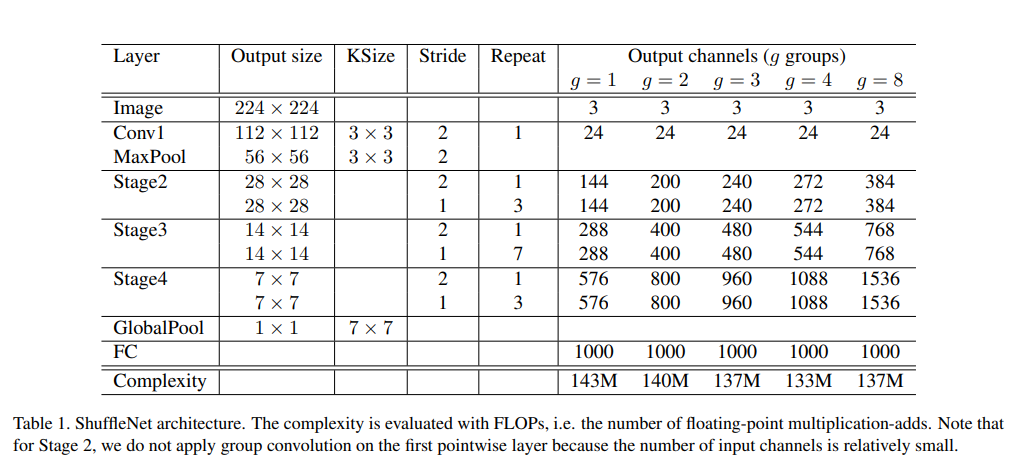
- [Table 1]을 보면, complexity 모두 비슷하게 맞춤, 즉 group의 수를 늘리면서 얻어진 이득(연산량 감소)에 따라 그만큼 channel 수를 늘린 것임
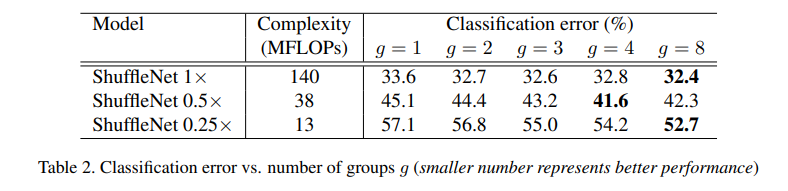
- [Table 2]를 보면, 대체적으로 group수가 증가함에 따라, 성능이 좋아지는 것을 확인할 수 있음
기타
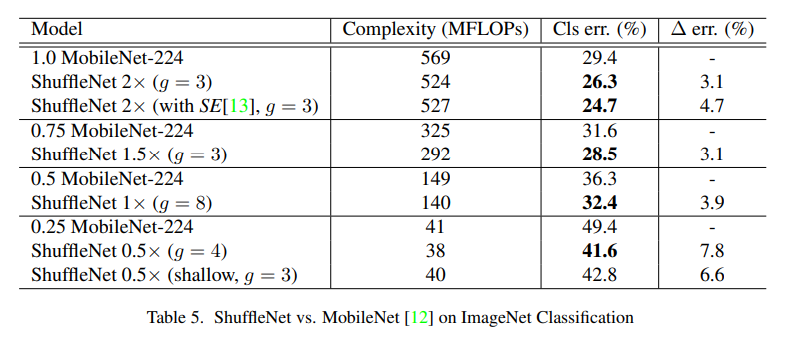
- 작은 네트워크일수록 feature map 수가 중요 => 줄어든 연산량 만큼 channel수를 늘리면, 더 많은 information을 추출하는 것이 가능
반응형
'머신러닝_딥러닝 > 모델 경량화' 카테고리의 다른 글
| (논문리뷰) AmoebaNet (작성예정) (0) | 2021.12.05 |
|---|---|
| (논문리뷰) EfficientNet (작성예정) (0) | 2021.12.01 |
| (논문리뷰) MobileNet v1 (0) | 2021.12.01 |
| 모델 경량화 기술 동향 (0) | 2021.12.01 |