논문 링크 : https://arxiv.org/pdf/1311.2524.pdf
Rich feature hierarchies for accurate object detection and semantic segmentation (CVPR 2014)
Contribution : Object Detection 분야에 최초로 Deep Learning(CNN)을 시도
Classification : 한 개의 객체(Object)가 무엇인지 알아내는 문제
Object Detection : 객체의 위치(Region of Interest) 및 종류에 대하여 알아내야 하는 문제
Object detection에는 1-stage detector, 2-stage detector가 있다.
1-stage detector : RoI영역을 먼저 추출하지 않고, 전체 image에 대해서 convolution network로 Classification, box regression(localization)을 수행
2-stage detector : RoI영역을 먼저 추출한 뒤, Classification, box regression(localization)을 수행
성능: Pascal VOC 2010을 기준으로 53.7%이며, 이미지 한 장에 CPU로는 47초, GPU로는 13초
R-CNN (2014) -> Fast R-CNN (2015) -> Faster R-CNN (2015) -> Mask R-CNN (2017)
학습구조
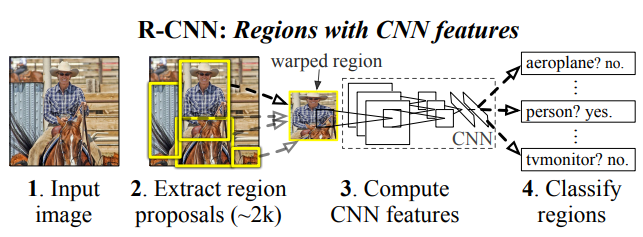
- Selective Search 알고리즘을 적용하여 물체가 있을만한 박스 2천개를 추출
- 227 x 227 크기로 리사이즈(warp)
- ImageNet dataset을 활용해 pre-trained된 CNN을 통과시켜, 4096 차원의 특징 벡터를 추출 (즉, 사전학습된 CNN을 가져와서, Object Detection용 데이터셋으로 fine tuning 한 뒤, selective search 결과로 뽑힌 이미지를 투입하여 특징 벡터를 추출)
- 추출된 벡터를 가지고 각각의 클래스(Object의 종류) 마다 학습시켜놓은 SVM Classifier를 통과시킴
- 바운딩 박스 리그레션을 적용하여 박스의 위치를 조정
Selective Search
주변 픽셀 간의 유사도를 기준으로 Segmentation을 만들고, 이를 기준으로 물체가 있을법한 박스를 추론
Non-Maximum Suppression
동일한 물체에 여러 개의 박스가 쳐져있는 것이라면, 가장 스코어가 높은 박스만 남기고 나머지는 제거 (IoU가 0.5 보다 크면 동일한 물체를 대상으로 한 박스로 판단하고 Non-Maximum Suppression을 적용)
Bounding Box Regression
Selective Search를 통해서 찾은 박스 위치는 부정확 -> 박스 위치를 교정
한계점
- Selective search로 2000개의 region proposal을 뽑고 각 영역마다 CNN을 수행하기 때문에 매우 느리다.
- CNN, SVM, Bounding Box Regression -> multi-stage pipelines으로 한 번에 학습되지 않는다. (즉, end-to-end 로 학습할 수 없음)

<Reference>
https://89douner.tistory.com/88
https://velog.io/@whiteamericano/R-CNN-%EC%9D%84-%EC%95%8C%EC%95%84%EB%B3%B4%EC%9E%90
'머신러닝_딥러닝 > Object Detection' 카테고리의 다른 글
| (논문리뷰) Yolo v1 (2016) (0) | 2021.09.13 |
|---|---|
| (논문리뷰) Faster R-CNN (0) | 2021.09.13 |
| (논문리뷰) Fast R-CNN (0) | 2021.09.13 |
| (논문리뷰) SENet (0) | 2021.01.15 |
| (논문리뷰) DenseNet (0) | 2021.01.15 |