Garbage Classification + Transfer Learning
Feature extractor : imagenet 데이터셋으로 사전훈련된 VGG16 모델
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.preprocessing.image import load_img, img_to_array, ImageDataGenerator
import matplotlib.pyplot as plt
import os, shutil
from tensorflow.keras.applications import VGG16
# 데이터셋 생성
dataset_dir = './data/Garbage classification/'
train_dir = os.path.join(dataset_dir, 'train')
validation_dir = os.path.join(dataset_dir, 'val')
train_gen = ImageDataGenerator(rotation_range=60, width_shift_range=0.3, shear_range=0.3,
horizontal_flip=True, zoom_range=0.3, rescale=1./255)
val_gen = ImageDataGenerator(rotation_range=60, width_shift_range=0.3, shear_range=0.3,
horizontal_flip=True, zoom_range=0.3, rescale=1./255)
train_generator = train_gen.flow_from_directory(train_dir, target_size=(240, 240), batch_size=32, class_mode='sparse')
validation_generator = train_gen.flow_from_directory(validation_dir, target_size=(240, 240), batch_size=32, class_mode='sparse')
# 모델 생성
feature_extractor = VGG16(weights='imagenet', include_top=False, input_shape=(240, 240, 3)) # include_top=False, 최상위 dense layer 포함여부
feature_extractor.trainable = False
model = Sequential()
model.add(feature_extractor)
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(6, activation='softmax'))
# 모델 컴파일 및 훈련시키기
model.compile(loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.Adam(), metrics=['accuracy'])
history = model.fit_generator(train_generator, steps_per_epoch=10, epochs=100,
validation_data=validation_generator, validation_steps=10)
# 훈련의 정확도 확인
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['train', 'validation'], loc='best')
plt.show()
|
cs |
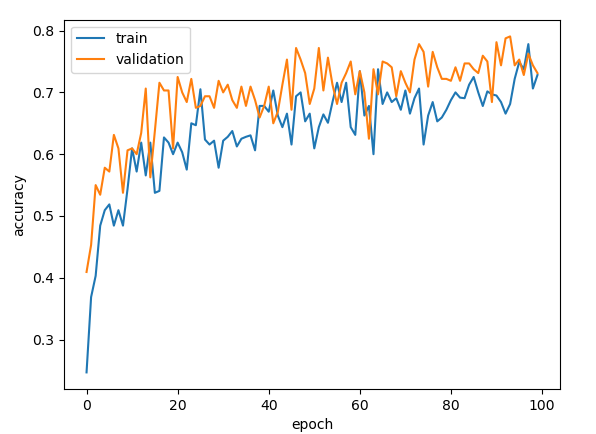
위의 소스코드를 실행시키면 아래와 같은 결과값을 얻을 수 있다.

파인 튜닝 : 특성 추출에 사용했던 모델의 상위 층 몇 개를 동결에서 해제하고, 새로 추가한 층(완전 연결 분류기)과 함께 훈련시킴
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.preprocessing.image import load_img, img_to_array, ImageDataGenerator
import matplotlib.pyplot as plt
import os, shutil
from tensorflow.keras.applications import VGG16
# 데이터셋 생성
dataset_dir = './data/Garbage classification/'
train_dir = os.path.join(dataset_dir, 'train')
validation_dir = os.path.join(dataset_dir, 'val')
train_gen = ImageDataGenerator(rotation_range=60, width_shift_range=0.3, shear_range=0.3,
horizontal_flip=True, zoom_range=0.3, rescale=1./255)
val_gen = ImageDataGenerator(rotation_range=60, width_shift_range=0.3, shear_range=0.3,
horizontal_flip=True, zoom_range=0.3, rescale=1./255)
train_generator = train_gen.flow_from_directory(train_dir, target_size=(240, 240), batch_size=32, class_mode='sparse')
validation_generator = train_gen.flow_from_directory(validation_dir, target_size=(240, 240), batch_size=32, class_mode='sparse')
# 모델 생성
feature_extractor = VGG16(weights='imagenet', include_top=False, input_shape=(240, 240, 3)) # include_top=False, 최상위 dense layer 포함여부
feature_extractor.trainable = True
train_flag = False
for layer in feature_extractor.layers:
if layer.name == 'block5_con1':
train_flag = True
if train_flag:
layer.trainable = True
else:
layer.trainable = False
model = Sequential()
model.add(feature_extractor)
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(6, activation='softmax'))
# 모델 컴파일 및 훈련시키기
model.compile(loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.Adam(), metrics=['accuracy'])
history = model.fit_generator(train_generator, steps_per_epoch=10, epochs=100,
validation_data=validation_generator, validation_steps=10)
# 훈련의 정확도 확인
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['train', 'validation'], loc='best')
plt.show()
|
cs |
반응형
'머신러닝_딥러닝 > Tensorflow + Keras' 카테고리의 다른 글
| (Tensorflow 2.x) 커스텀 Loss function (0) | 2021.11.14 |
|---|---|
| (Tensorflow 2.x) 함수형 API (0) | 2021.10.23 |
| (Tensorflow 2.x) CNN 2탄 (With Garbage Classification) (0) | 2021.10.23 |
| (Tensorflow 2.x) CNN 1탄 (With CIFAR-10 ) (0) | 2021.10.23 |
| (Tensorflow 2.x) Fashion MNIST (With CNN) (0) | 2021.10.23 |