- 지난 5년간의 테슬라 주가 변동 CSV파일 (가격변동률, 20·60일 이동평균선, 추가예정)

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
|
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Bidirectional, Flatten, Dense, Dropout
import matplotlib.pyplot as plt
import pandas as pd
# 데이터 프레임 데이터 만들기
# dictionary -> Dataframe
country_dict = {'Name':['USA', 'CHINA', 'RUSSIA', 'JAPAN', 'KOREA', 'EU', 'INDIA'],
'Capital':['Washington', 'Beijing', 'Moscow', 'Tokyo', 'Seoul', 'Brussels', 'New Delhi'],
'Income':[69375, 11891, 11273, 40704, 35195, 39152, 6390],
'Attractiveness':[84, 9, 11, 89, 62, 92, 36]}
country_df = pd.DataFrame(country_dict, columns=['Name', 'Capital', 'Income', 'Attractiveness'])
print(country_df.head())
country_df.to_csv('./country_ranking.csv', sep=',') # ',' 로 분리
country_df.to_csv('./country_ranking.tsv', sep='\t') # tab
country_df.to_csv('./country_ranking.txt', sep=' ') # 공백
# 데이터 프레임, 엑셀 파일로 저장하기
import xlwt
import openpyxl
country_df.to_excel('./country_ranking.xls')
country_df.to_excel('./country_ranking.xlsx')
# 데이터 프레임, json 파일로 저장하기
country_df.to_json('./country_ranking.json')
# csv 파일 불러오기
df = pd.read_csv('./TSLA.csv')
# header 정보가 없는 경우
# df = pd.read_csv('./TSLA.csv', header=None, names=['날짜', '시초가', '장중고가', '장중저가', '종가', '수정종가', '거래량'])
# tab으로 분리되어 있는 데이터 파일의 경우, df = pd.read_csv('./TSLA.txt', sep='\t')
print(type(df)) # <class 'pandas.core.frame.DataFrame'>
print(type(df.Close)) # <class 'pandas.core.series.Series'>
print(df.shape) # (1259, 7)
print(df.count()) # NaN는 세지 않음 -> 누락된 부분을 찾을 때 유용
print(df.head()) # 상위 5개 데이터
print(df.tail(14)) # 하위 14개
# 열(column) 추출
# df.열이름 또는 df['열이름'], df[['열이름1', '열이름2']]
# 데이터프레임에서 header가 없다면, df[:, 1:2] 처럼, 슬라이싱을 쓸 수 있음
df_1 = df['Open']
df_2 = df[['Open', 'Close']]
print(df_1)
print(df_2)
# 행(row) 추출
# 연속적인 데이터 -> 슬라이싱, 불연속적인 데이터 -> loc()
# df.iloc[1:3, 4:] 1행부터 2행까지, 4열부터 끝까지
# df.iloc[[2, 4], [2, 3]] 2행 4행, 2열 3열
df_3 = df.loc[0]
df_4 = df.loc[[0, 47]]
print(df_3)
print(df_4)
# 조건에 따른 데이터 추출
df_5 = df[df.Volume > 20000000]
df_6 = df[df.Date == '2016-11-21']
df_7 = df[(df.Low != 35.0) & (df.High >= 1000)]
print(df_5)
print(df_6)
print(df_7)
# 열 이름, 인덱스 변경
print(df.columns) # Index(['Date', 'Open', 'High', 'Low', 'Close', 'Adj Close', 'Volume'], dtype='object')
print(df.index) # RangeIndex(start=0, stop=1259, step=1)
# df.columns = ['날짜', '시초가', '장중고가', '장중저가', '종가', '수정종가', '거래량']
# df.index = ['하나', '둘', '셋']
# 열 삭제
df_8 = df.drop('Low', axis=1) # df_8 = df.drop(['Low', 'High'], axis=1)
print(df_8)
# 행 삭제
df_9 = df.drop(df.index[0]) # 원본에는 영향 없음, inplace=True 설정하면 원본에 영향
df_10 = df.drop(df.index[[0, 2]]) # 0행, 2행 삭제
print(df_9.head())
print(df_10.head())
# 열 추가 및 통계계산 (합계, 평균 등등)
sum_Close = df['Close'].sum(axis=0) # axis 인수에는 합계로 인해 없어지는 방향축(0=행, 1=열)을 지정, 즉 열방향 합계는 axis=0
ave_Close = df['Close'].mean()
print(sum_Close)
print(ave_Close)
df['Change_rate'] = (df['High'] - df['Low'])/df['Open']
df['20day_mean'] = df['Adj Close'].rolling(window=20).mean() # 이동평균 등을 쉽게 계산하기 위한 rolling() 메서드
df['60day_mean'] = df['Adj Close'].rolling(window=60).mean()
print(df.head())
print(df.tail())
# # 데이터프레임 합치기 (merge, concat)
#
# df11 = pd.DataFrame({
# '선수번호': [1001, 1002, 1003, 1004],
# '이름': ['김현수', '추신수', '류현진', '양현종']
# }, columns=['선수번호', '이름'])
#
# df12 = pd.DataFrame({
# '선수번호': [1001, 1001, 1005, 1006],
# '금액': [400, 200, 550, 310]
# }, columns=['선수번호', '금액'])
#
#
# df13 = pd.merge(df11, df12) # pd.join()과 동일, inner join, 공통 열인 선수번호를 기준으로 데이터를 합친다.
# df14 = pd.merge(df11, df12, how='outer') # outer join
#
# print(df13.head())
# print(df14.head())
#
#
# df15 = pd.DataFrame(
# np.arange(6).reshape(3, 2),
# index=['a', 'b', 'c'],
# columns=['c1', 'c2'])
#
# df16 = pd.DataFrame(
# 5 + np.arange(4).reshape(2, 2),
# index=['a', 'c'],
# columns=['c3', 'c4'])
#
# df17 = pd.concat([df15, df16]) # 단순히 데이터를 연결(concatenate), 행 방향으로 합침
# df18 = pd.concat([df15, df16], axis=1) # 열 방향으로 합침
#
# print(df17.head())
# print(df18.head())
#
#
# # 기타
# # NaN 값은 fillna()를 사용하여 원하는 값으로 바꿀 수 있다.
|
cs |
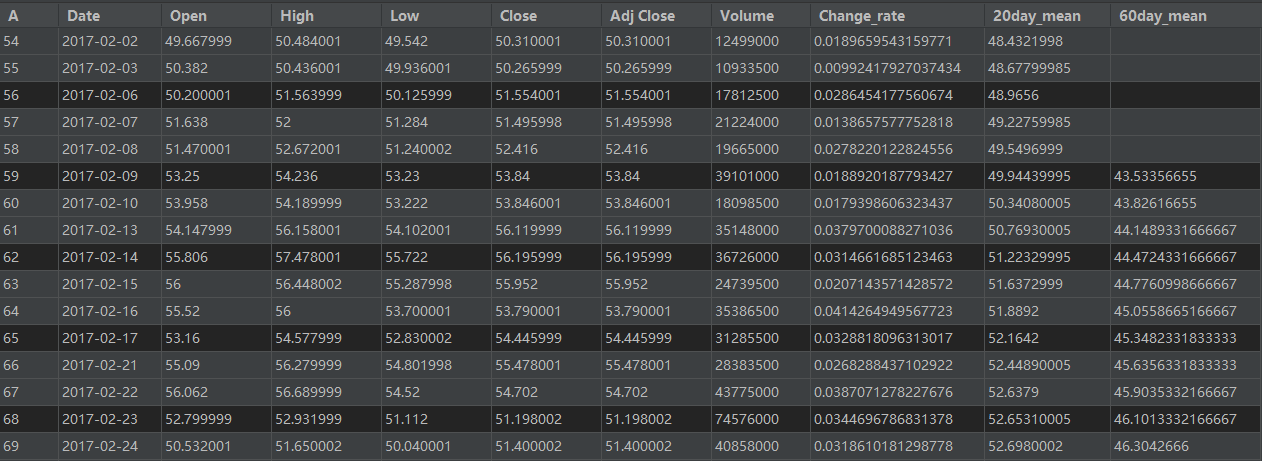
아래와 같은 csv 파일을 얻을 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
|
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout, BatchNormalization
from tensorflow.keras.callbacks import EarlyStopping
# 데이터 로드 및 확인
df = pd.read_csv('./Revised_TSLA.csv')
print(df.head())
# plt.title('Tesla stock price')
# plt.xlabel('day')
# plt.ylabel('doller')
# plt.grid()
# plt.plot(df['Adj Close'], color='r')
# plt.show()
# 데이터 전처리
# 특이값 : 비정상적으로 크거나 작은 데이터 -> 적절한 값으로 변경하거나 삭제 필요
# 결측값 : 예를 들어 거래량이 0인 경우(국경일 등) -> NaN
print(df.isnull().sum()) # 금융데이터에서는 결측값은 평균값 등으로 대체하지 않고, 행 전체를 삭제하는 것이 일반적
print(df.loc[df['20day_mean'].isna()])
print(df.loc[df['60day_mean'].isna()])
df['20day_mean'].replace(0, np.nan) # 0을 NaN으로 대체
df['60day_mean'].replace(0, np.nan)
print(df.isnull().sum())
df = df.dropna() # 결측값 삭제
print(df.isnull().sum())
# 정규화
scaler1 = MinMaxScaler()
scaler2 = MinMaxScaler()
scaled_df = scaler1.fit_transform(df[['Open', 'High', 'Low', 'Close',
'Volume', 'Change_rate', '20day_mean', '60day_mean']])
scaled_df_label = scaler2.fit_transform(df[['Adj Close']])
scaled_df = pd.DataFrame(scaled_df, columns=['Open', 'High', 'Low', 'Close',
'Volume', 'Change_rate', '20day_mean', '60day_mean'])
scaled_df_label = pd.DataFrame(scaled_df_label, columns=['Adj Close'])
feature_cols = ['Open', 'High', 'Low', 'Close',
'Volume', 'Change_rate', '20day_mean', '60day_mean']
label_cols = ['Adj Close']
feature_df = pd.DataFrame(scaled_df, columns=feature_cols)
label_df = pd.DataFrame(scaled_df_label, columns=label_cols)
feature_numpy = feature_df.to_numpy()
label_numpy = label_df.to_numpy()
# 데이터셋 생성
window_size = 30
def makeDataset(x_data, y_data, window_size):
temp_x = []
temp_y = []
for i in range(len(x_data) - window_size):
x = x_data[i:(i + window_size)]
y = y_data[i + window_size]
temp_x.append(x)
temp_y.append(y)
return np.array(temp_x), np.array(temp_y) # (4, 5) -> (1, 4, 5)
x_train, y_train = makeDataset(feature_numpy, label_numpy, window_size) # (1170, 30, 8), (1170, 1)
x_test = x_train[-100:]
y_test = y_train[-100:]
x_val = x_train[-200:-100]
y_val = y_train[-200:-100]
x_train = x_train[0:-200]
y_train = y_train[0:-200]
# 모델 생성
def make_model():
model = Sequential()
model.add(LSTM(128, activation='tanh', return_sequences=True, input_shape=(30, 8)))
model.add(LSTM(128, activation='tanh', recurrent_dropout=0.2))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1, activation='linear'))
return model
model = make_model()
# 모델 컴파일 및 학습
model.compile(loss='mse', optimizer=tf.keras.optimizers.RMSprop(), metrics=['mae'])
early_stopping = EarlyStopping(monitor='val_loss', patience=5)
model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=2, batch_size=16, callbacks=[early_stopping])
# 모델 예측
prediction = model.predict(x_test)
prediction = scaler2.inverse_transform(prediction)
y_test = scaler2.inverse_transform(y_test)
plt.figure(figsize=(12, 6))
plt.title('Tesla stock price prediction')
plt.xlabel('day')
plt.ylabel('predicted price')
plt.plot(y_test, label='actual')
plt.plot(prediction, label='model prediction')
plt.grid()
plt.legend(loc='best')
plt.show()
|
cs |
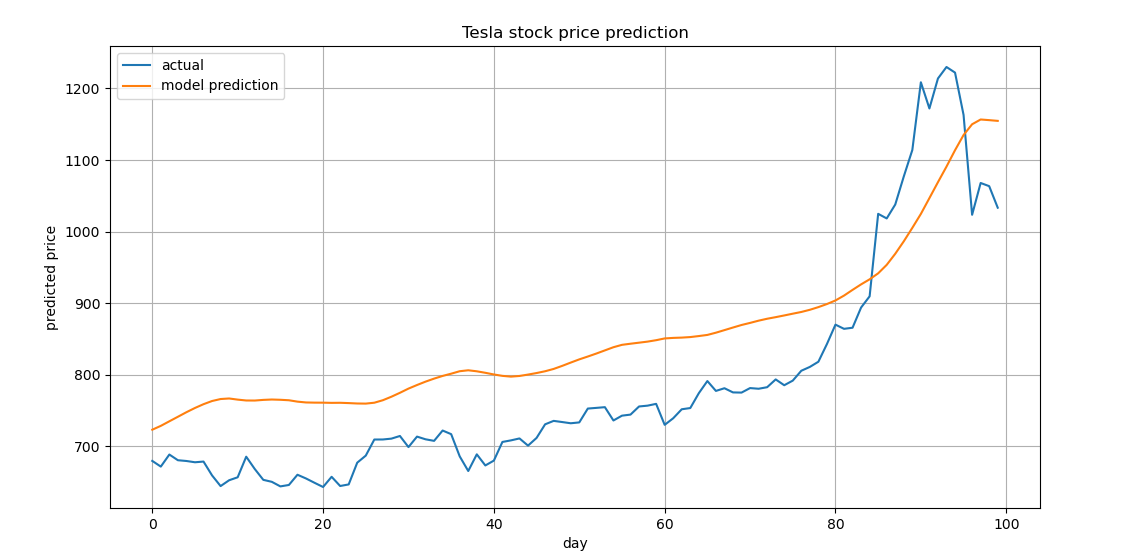
과거 5년간의 주가 데이터를 바탕으로 최근 100일간의 주가 흐름을 모델이 예측 후, 실제 주가 흐름과 비교
반응형
'머신러닝_딥러닝 > Tensorflow + Keras' 카테고리의 다른 글
| Image Annotation Formats (0) | 2021.12.02 |
|---|---|
| GPU 서버, 사용 방법 (0) | 2021.11.27 |
| (Tensorflow 2.x) LSTM & GRU (0) | 2021.11.14 |
| (Tensorflow 2.x) RNN (0) | 2021.11.14 |
| (Tensorflow 2.x) 커스텀 Loss function (0) | 2021.11.14 |